Kitex 两周年回顾 — 能力升级、社区合作与未来展望
项目:
本篇文章是 CloudWeGo 两周年庆典系列的第一篇。
今天的分享主要分成三个部分,首先是 Kitex 的能力升级,看一下过去一年在性能、功能和易用性这个方面上的一些进展。第二个是社区合作项目的进展,特别是其中两个重点项目 Kitex-Dubbo 互通以及配置中心集成。第三个是给大家剧透一下我们目前在做以及计划做的一些事情。
能力升级
性能
在2021年9月,我们曾发布了一篇字节跳动 Go RPC框架 Kitex 性能优化实践, 这篇文章介绍了如何通过自研网络库 Netpoll、及自研的 Thrift 编解码器 fastCodec 来优化 Kitex 的性能。
自那时起,提升 Kitex 核心请求链路上的性能就非常困难了,实际上我们是要努力,在不断地添加新功能的同时,避免 Kitex 性能下降。
尽管如此,我们一直没有停止优化 Kitex 性能的尝试。在字节内部,我们已经在试验、推广一些在核心链路上的性能提升,稍后会再给各位介绍。
基于 DynamicGo 的泛化调用
首先介绍一个已经发布的性能优化:基于 DynamicGo 的泛化调用。泛化调用是 Kitex 的一个高级特性,能够在不预先生成 SDK 代码(也就是 Kitex Client)的前提下,使用 Kitex Generic Client 直接调用目标服务的 API。
例如字节跳动内部的 接口测试工具、API 网关等,就使用了 Kitex 的泛化 Client,能够接收一个 HTTP 请求(请求体是 JSON 格式),转换成 Thrift Binary 后,发送给 Kitex Server。
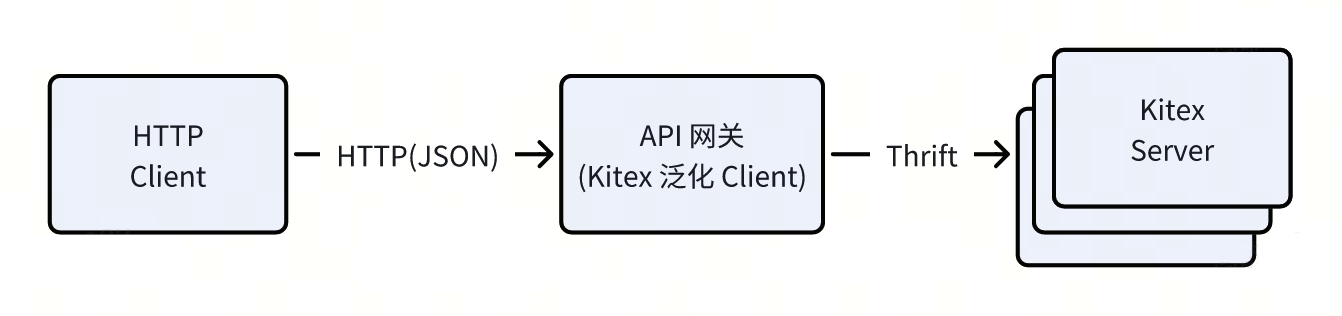
其实现方案是依赖一个 map[string]interface{} 作为泛型容器,请求时先将 json 转换为 map,在基于 Thrift IDL 完成 map -> thrift 的转换;对响应的处理则反过来。
- 这样做的好处是灵活性高,不需要依赖预先生成的静态代码,只需要有 IDL 就可以请求目标服务;
- 但是其代价是性能较差,这样一个泛型容器依赖 Go 的 GC 和 内存管理,开销巨大,不仅需要分配大量内存,还需要多次数据拷贝。
因此我们开发了 DynamicGo,可用于提升协议转换的性能。项目 introduction 里有非常详细的介绍,这里只给大家介绍其核心设计思路:基于原始字节流,原地完成数据处理和转换。
DynamicGo 通过池化技术,能实现只需要预分配一次内存,并使用 SSE、AVX 等 SIMD 指令集进行加速,最终实现了非常可观的性能提升。
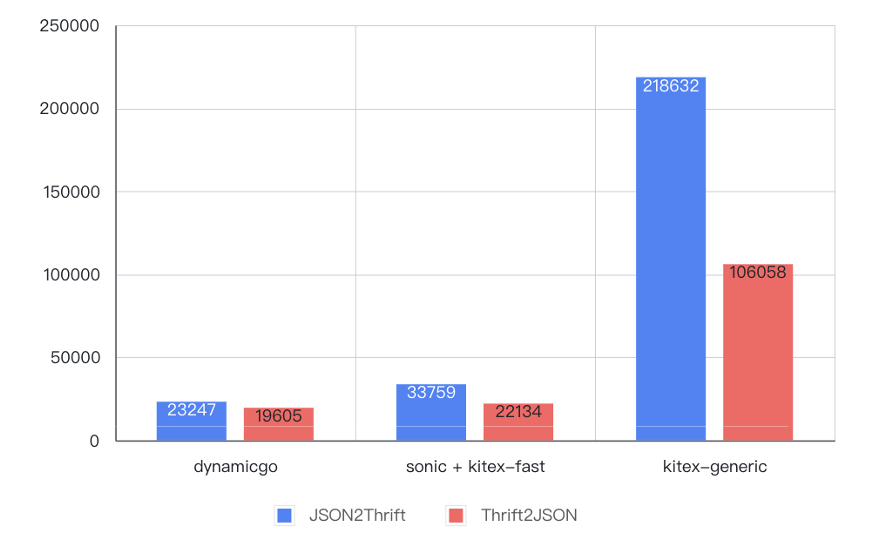
如下图所示,相比原泛化调用的实现,在 6KB 数据的编解码测试中,性能提升了 4~9 倍,甚至优于预先生成的静态代码。
其实际原理很简单:根据解析 IDL 生成类型描述符 Descriptor,执行如下协议转换过程
- 每次从 JSON 字节流中读取一个 Key/Value pair;
- 根据 IDL Descriptor 里找到 key 对应的 Thrift 字段;
- 按相应类型的 Thrift 编码规范完成 Value 的编码,并写入输出字节流;
- 循环这个过程,直到处理完整个 JSON。
DynamicGo 除了可以优化 JSON/Thrift 的协议转换,还提供了 Thrift DOM 方式用于优化数据编排场景的性能。例如抖音某业务团队需要擦除请求中的违规数据,但仅限请求中的某一个字段;使用 DynamicGo 的 Thrift DOM API 就非常适合,可以实现 10 倍的性能提升,详情可参考 DynamicGo 的文档,这里就不展开了。
Frugal - 基于 JIT 的高性能 Thrift 编解码器
Frugal 是一个 基于 JIT 编译技术的高性能 Thrift 编解码器。
Thrift 官方以及 Kitex 默认的编解码器都是基于解析 Thrift IDL,生成相应的编解码 Go 代码。通过 JIT 技术,我们能够在运行时动态生成性能更好的编解码代码: 生成更紧凑的机器码、减少 cache miss、减少 branch miss,用 SIMD 指令来加速,使用基于寄存器的函数调用(Go 默认是基于栈)。
这里给出了编解码测试的性能指标:

可以看到,Frugal 性能显著高于传统方式。
除了性能上的优势,由于可以不生成编解码代码,也有额外的好处。
一方面仓库更简洁了,我们有一个项目,生成的代码有 700MB,切换到 frugal 后只有 37M,大约只有原来的 5%,在仓库维护方面压力大幅缩小,修改 IDL 以后也不会生成一大堆实际上无法 review 的代码; 另一方面 IDE 的加载速度、项目的编译速度也能显著提高。
其实 Frugal 去年就已经发布了,但是当时的早期版本覆盖不够充分。今年我们重点优化了它的稳定性,修复了所有已知问题, 最近发版的 v0.1.12 版本,可以稳定地使用在生产业务上。例如字节跳动电商业务线,某服务的峰值 QPS 约 25K,已经全量切换到 Frugal,稳定运行了数月。
Frugal 目前支持 Go1.16 ~ Go1.21,暂时只支持 AMD64 架构,未来也将支持 ARM64 架构;我们可能会在未来某个版本将 Frugal 作为 Kitex 的默认编解码器。
功能
Kitex 在过去一年中从 v0.4.3 升级到 v0.7.2,其中 Feature 相关的 Pull Request 共有 40 多个,涵盖了命令行工具、gRPC、Thrift 编解码、重试、泛化调用、服务治理配置等多个方面,这里重点介绍几个比较重要的特性。
Fallback - 业务自定义降级
首先是 Kitex 在 v0.5.0 版本新增的 fallback 功能。
需求背景是,业务代码在 RPC 请求失败、无法获得响应时,往往需要执行一些降级策略。
例如信息流业务,API 接入层在请求推荐服务时,如遇到偶发错误(例如超时),简单粗暴的做法是告诉用户出错了,让用户重试,但这样体验就很差。一个比较好的降级策略是,尝试返回一些热门条目,用户几乎无感,体验相对就好了很多。
旧版 Kitex 的问题是,业务自定义的 中间件 在熔断、超时等内置中间件之后,因此无法在 middleware 里实现降级策略,只能直接修改业务代码,侵入性较大,且需要修改每一处方法调用,容易遗漏。在新增调用某方法的业务逻辑时,没有机制保证不被遗漏。
通过新增的 fallback 功能, 允许业务在初始化 Client 时指定一个 fallback 方法来实现降级策略。
下面是一个简单的使用示例:

初始化 client 时指定的这个方法会在每次请求结束前被调用,可以获得这次请求的 context、请求参数、响应,基于此实现自定义的降级策略,这样就把策略的实现都收敛起来了。
Thrift FastCodec - 支持 unknown fields
在实际的业务场景中,一个请求链路往往涉及多个节点。
以链路 A -> B -> C -> D 为例,A 节点的某个 struct 需要通过 B、C 透传到 D 节点。在以往的实现里,如果在 A 新增一个字段,例如 Extra,
我需要使用新的 IDL 重新生成所有节点的代码,重新部署,才能在 D 节点获得 Extra 字段的值。整个流程比较复杂,更新周期也比较长,如果中间节点是其他团队的服务,还需要跨团队协调,非常吃力。
在 Kitex v0.5.2 里,我们在自研的 fastCodec 里实现了 Unknown Fields 这个特性,可以很好地解决这个问题。
例如同样是 A -> B -> C -> D 这个链路,B、C节点代码不变(如下图所示),在解析时,发现有个字段 id=2,在 struct 里找不到对应的字段,于是就写入这个未导出的 _unknownFields 字段(实际上就是一个 byte slice 的别名);

而 A、D 服务是用新 IDL 重新生成过的(如下图所示),包含了 Extra 字段,因此解析到 id=2 的字段时,可以写到这个 Extra 字段,业务代码就可以正常使用了。

此外,我们在 v0.7.0 还对这个特性进行了一次性能优化,使用「无序列化」(直接拷贝字节流)的方式,将 unknown fields 的编解码性能提升了约 6~7 倍。
基于 GLS 的 Session 传递机制
另一个值得给各位介绍的特性也和长链路有关。
在字节内部,我们用 LogID 来追踪整个调用链,这就要求链路中所有节点都能按要求透传这个票据。在我们的实现中,LogID 不是放在请求体里,而是以 metadata(元数据)的形式透传。
以 A -> B -> C 这个链路为例,A 调用 B 的 A_Call_B 方法,传入的 LogID 会存放在 handler 入参的 ctx 里;B 在请求 C 时,正确的用法是,将这个 ctx 传给 clientC.B_Call_C 方法,这样才能把 LogID 继续传递下去。

但是实际情况往往是,请求 C 服务的代码被多层包装,ctx 的透传就容易被遗漏;我们遇到的情况更麻烦,对 C 服务的请求是由第三方库完成的,而该库的接口就不支持传入 ctx,而这样的代码改造成本很高,可能需要协调多个团队才能完成。
为了解决这个痛点,我们引入了基于 GLS(goroutine local storage)的 session 传递机制。具体方案是:
- 在 Kitex Server 这边,收到请求后,先将 context 备份在 GLS 里,然后再调用 Handler ,也就是业务代码;
- 在业务代码里调用 client 发送请求时,先检查入参的 ctx 里是否包含期望的票据,如果没有,则从 GLS 的备份里取出,再发出请求。
下面是一个具体例子:

说明:
- 初始化 Server 的时候打开
ContextBackup开关 - 初始化 Client 的时候指定一个
backupHandler - 每次发出请求前,会调用该 handler,检查入参是否包含了
LogID - 如果不包含,从备份的
ctx里读出,合并到当前ctx里返回(返回useNewCtx = true表示 Kitex 应使用这个新的ctx发请求)
在开启上述设置后,即使业务代码使用了错误的 context,也能够串联起整个链路。
最后再介绍下 server 初始化的 async 参数,它解决的是在 handler 里新建 goroutine 里发送请求的情况。 由于不是同一个 goroutine,无法直接共享 Local Storage;我们借鉴 pprof 给 goroutine 染色的机制,将备份的 ctx 也传递给新的 goroutine,这样就实现了在异步场景也能隐式传递票据的能力。
易用性
除了高性能和丰富的功能,我们也很注重提高 Kitex 的易用性。
文档
众所皆知,程序员最讨厌的两件事:一是写文档,二是别人不写文档。因此我们很注重降低编写文档的启动成本,并努力推进文档建设。
在字节跳动内部,Kitex 的文档是以飞书知识库的形式组织的,能够更好地集成到飞书的搜索,方便字节员工查询;由于飞书文档更新方便,因此比官网文档更新更及时;新功能在开发时往往也是先在飞书知识库中撰写文档,有些没有及时同步到官网。各种原因导致内外两个分支差别越来越大。
因此最近两个季度,我们发起了新一轮文档优化工作:根据用户的反馈,重新整理所有文档,添加更多示例;将所有文档翻译成英文,同步到官网。这项工作预计今年能完成,目前已经能在官网看到一些更新后的文档了,例如超时控制、Frugal、panic 处理等,欢迎各位到官网围观、帮忙捉虫。
此外,我们还在搭建一套机制,用于自动化将内部文档同步到官网,希望能让开源用户以后也能像内部用户一样得到及时更新的文档。
其他优化
除了文档, Kitex 还做了一些其他易用性相关的工作。
我们发布了一个示例项目笔记服务,在实例中展示中间件、限流、重试、超时控制等各种特性的用法,通过真实的项目代码给 Kitex 用户提供参考。
其次我们也在努力提高问题排查的效率,例如我们根据日常 oncall 的需求,在报错信息里添加了更具体的上下文信息(诸如超时报错增加具体原因、panic 信息增加 method name、thrift 编解码错误信息增加具体字段名称等),方便快速定位到具体的问题点。
此外,Kitex 命令行工具也在持续改进。
- 例如很多企业用户是在 Windows 上开发,之前 Kitex 无法正常在 Windows 下生成代码,导致这些用户还需要一个 Linux 环境来辅助,非常不方便,我们根据这些用户的反馈做了优化。
- 我们还实现了一个 IDL 裁剪工具,能够识别出没有被引用的结构体,在生成代码时直接过滤掉,这对于一些包浆的老项目非常有帮助。
社区合作项目
过去的一年里,在 CloudWeGo 社区的支持下,我们也取得了很多成果,特别是 Dubbo 互通和配置中心集成这两个项目。
Dubbo 互通
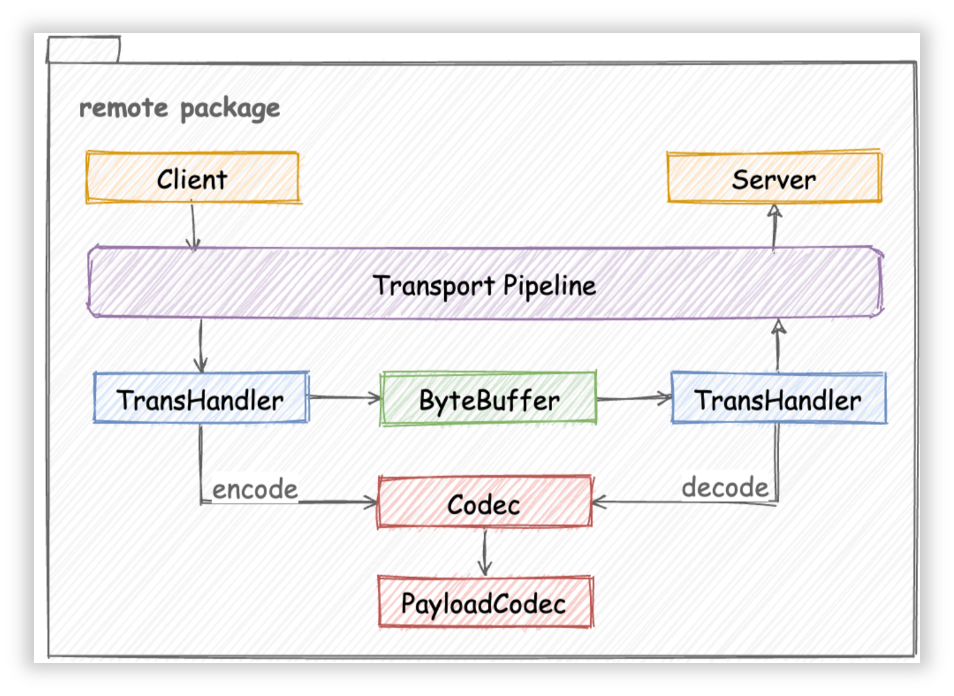
虽然 Kitex 最初是一个 Thrift RPC 框架,但是其架构设计有较好的扩展性,如图所示,增加新的协议,核心工作是按 Codec 接口实现一个对应的协议编解码器(Codec 或者 PayloadCodec):
Dubbo 互通项目源于某企业用户提出的需求,他们有一些供应商是用 Dubbo Java 实现的外围服务,他们希望也能够使用 Kitex 来请求这些服务,降低项目的管理成本。
这个项目得到了社区同学的热情支持,有很多同学参与到这个项目中。特别地,承担核心任务之一的 @DMwangnima 同学,同时也是 Dubbo 社区的开发者,由于他对 Dubbo 比较熟悉,开发过程也少走了很多弯路。
在具体实现方案上,我们采用了和 Dubbo 官方不同的思路。根据对 hessian2 协议的分析,其基础类型系统基本上是和 Thrift 重合的,因此我们基于 Thrift IDL 来生成 Kitex Dubbo-Hessian2 项目脚手架。
一期为了快速实现功能,我们直接借用了 Dubbo-go 框架的 hessian2 库来做序列化和反序列化,并参考 Dubbo 官方文档和 Dubbo-Go 的源码,实现了 Kitex 自己的 DubboCodec;
在 10 月我们已经完成了第一版代码,项目地址是 code-dubbo ,感兴趣的用户可以按照上面的文档试用,在具体的使用上,和 Kitex Thrift 类似,写好 Thrift IDL,用 kitex 命令行生成脚手架(注意需要指定 Protocol 为 hessian2),然后在代码里初始化 client、server 的地方指定 DubboCodec,就可以开始编写业务代码了。
这不仅降低了用户使用门槛,而且用 IDL 来管理接口相关信息,可维护性也更好。
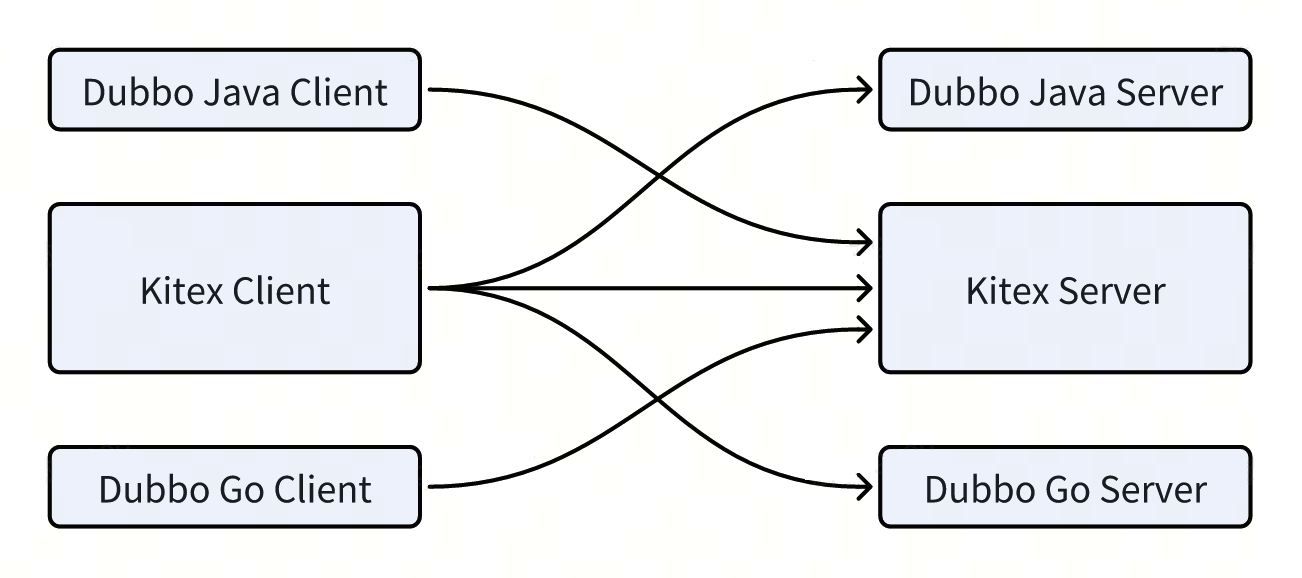
目前我们已经能够做到 Kitex 和 Dubbo-Java、Kitex 和 Dubbo-Go 互通:
未来计划:
- 首先是提高与 dubbo-java 的兼容性,以及允许用户在 IDL 注解里指定对应的 Java 类型。
- 其次是与注册中心的对接。虽然 Kitex 已经有对应的注册中心模块,但具体的数据格式和 Dubbo 不一致,这块还需要一些改造,相关工作即将完成。
- 最后是性能问题,目前和 Kitex Thrift 相比有较大差距,因为 dubbo-go-hessian2 这个库完全基于反射实现,性能还有很大优化空间。计划实现 Hessian2 的 FastCodec,从而解决编解码的性能瓶颈。
在这个项目的推进过程中,我们深切体验到跨社区合作的积极影响,Kitex 吸收了 Dubbo 社区的成果,同时也发现了 Dubbo-go 项目可以改进的地方,上面说到的兼容性和性能的解决方案,预计也能反哺 dubbo 社区。
在此也特别向这个项目的社区贡献者 @DMwangnima、@Lvnszn、@ahaostudy、@jasondeng1997、@VaderKai 等同学致谢,感谢他们抽出大量业余时间完成这个项目。
配置中心集成
另一个社区合作的重点项目是「配置中心集成」。
Kitex 提供了可动态配置的服务治理能力,包括客户端的超时、重试、熔断,以及服务端的限流。
这些服务治理能力在字节内部都是被重度使用的,微服务的开发者可以在字节自建的服务治理配置平台上编辑这些配置,粒度细化到这个五元组,并且是准实时生效,这些能力对提高微服务的 SLA 非常有帮助。
然而我们和企业用户沟通,发现这些能力通常只有非常简单的使用,粒度很粗,而且时效性较差,可能只是硬编码指定配置,或者通过简单的文件配置,需要重启才能生效。
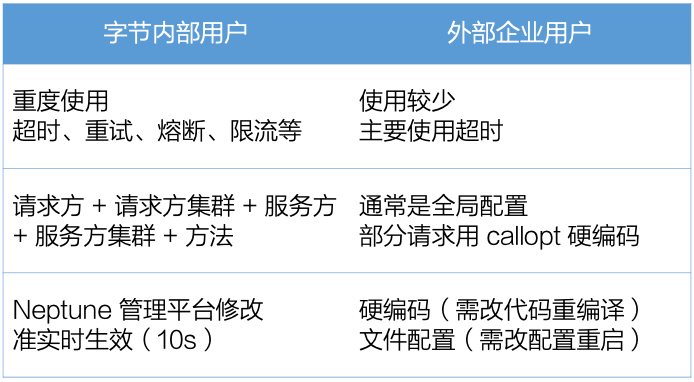
为了让用户能够更好地用上 Kitex 的服务治理能力,我们启动了配置中心集成项目,让 Kitex 能够从用户的配置中心动态获取服务治理配置,并准实时生效。
我们已经发布了 config-nacos 的 v0.1.1 版本(注:截至发文时已更新至 v0.3.0,感谢 @whalecold 同学的持续投入),通过在现有 Kitex 项目上给 client 增加 NacosClientSuite,可以很简单地让 Kitex 从 Nacos 加载对应的服务治理配置。

由于我们使用 nacos client 本身提供的 watch 能力,可以准实时地收到配置的变更通知,因此时效性也很强,不需要重启服务。
此外,我们还预留了修改配置粒度的能力,例如默认的配置粒度是 client + server,在 Nacos 的 data id 里按这个格式填写即可;用户也可以通过指定这个 data id 的模板,例如加上机房、集群等,从而更精细化地调整这些配置。
我们计划完成对接常见的配置中心,在这个 issue 里有更详细的说明,欢迎大家围观。 目前的进展是:
感兴趣的同学的同学也可以参与进来,一起 review、测试验证这些扩展模块。
未来展望
最后给大家剧透一下我们目前正在尝试的一些方向。
合并部署
亲和性部署
我们之前的优化大多是针对服务内,而随着可优化点逐渐减少,我们开始考虑其他目标,比如优化 RPC 请求在网络通信上的开销。 具体的方案如下:
- 首先是亲和性调度,通过修改容器化调度机制,我们将 Client 和 Server 尽量调度到相同的物理机上;
- 于是我们就可以用同机通信来降低开销。
目前我们已经实现的同机通信包括如下三种:
- Unix Domain Socket,比标准的 TCP Socket 性能要好一些,但不太多;
- ShmIPC,基于共享内存的进程间通信,这个可以直接省略序列化数据的传递,只需要把内存地址告诉接收方即可;
- 最后是 RPAL 这个「黑科技」,这是 Run Process As Library 的缩写,我们和字节的内核组合作,通过定制化的内核,将两个进程放在同一个地址空间,在满足一定条件的情况下,我们甚至可以不需要做序列化;
目前我们已经在 100 多个服务上开启了这个能力,也取得了一些性能收益,对于效果比较好的服务,能够节省约 5~10% 的 CPU,耗时也能减少 10~70%;当然实际表现取决于服务的一些特性,例如数据包的大小等。
编译期合并
另一个思路是编译期合并。
该方案的出发点是,我们发现微服务虽然提升了团队协作的效率,但是也增加了系统整体复杂性,尤其是在服务部署、资源占用、通信开销等方面。
因此我们希望实现一种方案:让业务既能够以微服务的形式开发,又能够按单体服务的形式部署,俗称既要又要。
然后我们把这个方案做出来了 —— 我们开发了一个工具,能够把两个微服务的 git repo 合并在一起,并通过 namespace 隔离可能有冲突的资源,然后编译成一个可执行程序,用于部署。
目前在字节跳动内部,已经有数十组服务接入,效果最好的服务,CPU 节省约80%,延迟则能降低最多 67%;当然,实际表现也取决于该服务的特性,比如请求包的大小。
以上是我们在亲和性方面的尝试。
序列化
在序列化方面,我们也还在做一些努力和尝试。
Frugal - SSA Backend
首先是 Frugal,前面介绍过它的性能已经显著优于传统的 Thrift 编解码代码,但它还有提升空间。
目前 Frugal 的实现是用 Go 直接生成对应的汇编代码。我们在具体实现中也应用了一些优化手段,例如生成更紧凑的代码,减少分支等;但光靠我们自己这样写,无法充分利用现有的编译器优化技术。
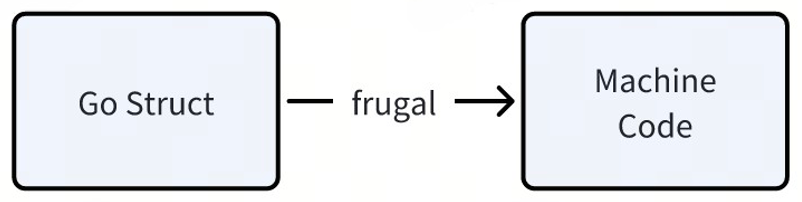
我们计划将 Frugal 重构后,能够基予 go struct 先生成符合 SSA 的 LLVM IR(即 Intermediate Representation,中间表示),这样就能够充分利用 LLVM 的编译优化能力。

预计这样改造后,性能可以提升至少 30%。
按需序列化
在另外一个探索方向是按需序列化,具体又可以分成三块。
首先是编译前。我们目前已经发布了一个 IDL 裁剪工具,能够识别出没有被引用的类型;但是被引用的类型也可能是不需要的,例如A、B两个服务依赖同一个类型,但其中有一个字段可能A需要,B不需要。我们考虑在这个工具上增加用户标注能力,允许用户指定不需要的字段,从而进一步降低序列化开销。
其次是编译中。其思路是根据编译器的编译报告来获取实际违背业务代码引用的字段进行裁剪。具体的方案和正确性还需要一些验证。
最后是编译后,在运行时,也允许业务通过指定不需要的字段,从而节省编解码的开销。
总结
最后我们整体回顾一下:
在能力升级方面,
- Kitex 通过 DynamicGo 优化了泛化调用的性能,高性能 Frugal 编解码器也已经稳定,可用于生产环境了;
- 过去一年新增了 fallback 方便业务实现自定义降级策略,并通过 unknown fields 和 session 传递机制来解决长链路的改造问题;
- 我们还通过文档优化、demo 项目、问题排查效率改造 和 增强命令行工具等方式提升了 Kitex 的易用性;
在社区合作方面,
- 我们通过 Kitex - Dubbo 互通项目支持了 Dubbo 的 hessian2 协议,可以和 Dubbo Java、Dubbo-Go 框架互通,并且还有后续的优化,也能反哺 Dubbo 社区;
- 在配置中心集成项目中,我们发布了 Nacos 扩展,方便用户集成,目前还在继续推进其他配置中心的对接;
未来还有一些探索方向,
- 在合并部署方面,我们通过亲和性部署、编译其合并这两种方式,既能保留微服务的好处,又能享受一部分单体不服务的优势;
- 在序列化方面,我们还继续进一步优化 Frugal,并且通过编译前中后各环节来实现按需序列化的能力;
以上是在 CloudWeGo 两周年之际,关于 Kitex 的回顾和展望,希望对大家有帮助,谢谢。